
Agent Skills: más poder, menos tokens
Progressive disclosure para context windows: carga solo lo que necesitas, cuando lo necesitas


Tengo una confesión: he estado usando Claude Code como si el context window (el ‘espacio de memoria’ disponible para el agente) fuera infinito.
Conecté el MCP (Model Context Protocol, el estándar para conectar agentes a herramientas externas) de Atlassian para revisar Jira. Después el de Notion para consultar docs. Después mi base de datos interna. Después el de dbt. Cada conector útil por sí solo. Pero juntos, un problema silencioso.
Abrí una sesión nueva para escribir código. Antes de escribir una línea, Claude Code ya había utilizado 95k tokens de los 200k de la context window.
¡¿QUÉ?!
No habia escrito nada. No había pedido nada. Solo abrí el editor.
Resulta que cada MCP carga su metadata completa al inicio: schemas de API, documentación de funciones, ejemplos de uso. Todo “por si acaso” lo necesito. Y en cada sesión se repite. Esos tokens consumidos son espacio en el context window desperdiciado antes de empezar a trabajar.
En diciembre de 2025, GitHub Copilot y Anthropic estandarizaron la solución: Agent Skills. Y resulta que no es solo para quienes construyen agentes: es para cualquiera que use Claude Code, GitHub Copilot, o cualquier herramienta “agentica”.
Te voy a mostrar exactamente qué son, por qué importan, y cómo esto cambia la economía de trabajar con agentes de IA.
El problema real: las context windows son preciosas
Conectas MCPs para Jira, para Notion, para tu base de datos, para dbt. Todos son útiles pero piensa: ¿usas todos en cada sesión?
Probablemente no. Jira lo necesitas en la primera sesión del día. Pero lo cargas en cada sesión el resto del día.
Costo visible: 50k tokens antes de hacer nada.
Costo invisible: Cuando el agente necesita más contexto, tiene que compactar mensajes anteriores para hacer espacio. Pierdes detalles. El agente “olvida” lo que discutieron hace 10 minutos.
Cuando pagas APIs en dólares pero cobras en pesos, 50k tokens desperdiciados no es “ineficiencia” es dinero tirado a la basura.
Y si construyes tus propios agentes (como mis seis "empleados" de IA), el problema se multiplica. Cada habilidad que agregas (generar imágenes, validar datos, formatear documentos) consume contexto antes de que el usuario escriba algo. Y aunque el agente acierte, gasta tokens razonando cómo hacerlo. Tú ya sabes los pasos. ¿Para qué pagar para que el agente los redescubra una y otra vez?
El patrón es el mismo: todas las habilidades se cargan desde el inicio, llenando el context window con información que probablemente no vas a usar en esta sesión.
Cuando quieres agregar otro MCP—Mixpanel para analytics, Vercel para deploys, Cloudflare—tienes que elegir. ¿Qué saco del context window para hacer espacio?
El estándar de Agent Skills cambió esto.
¿Qué son los Agent Skills? (Enseñar, no cargar)
Agent Skills son archivos markdown que enseñan a los agentes workflows especializados. Pero solo se cargan cuando son relevantes.
Piénsalo como darle un manual de procedimientos a alguien, pero que solo abre el capítulo que necesita en el momento exacto en que lo necesita.
La estructura
Un skill es un directorio con un archivo SKILL.md. Eso es lo mínimo:
.claude/skills/image-generation/
└── SKILL.mdOpcionalmente, puedes agregar subdirectorios para recursos adicionales:
image-generation/
├── SKILL.md # Instrucciones + metadata YAML
├── references/ # (opcional) Documentación, ejemplos
└── scripts/ # (opcional) Scripts reutilizablesEl SKILL.md tiene dos partes:
1. Metadata YAML:
---
name: image-generation
description: Usa este skill para crear ilustraciones o contenido visual con Gemini API
---2. Instrucciones (markdown):
# Generación de Imágenes
Cuando el usuario pida una imagen:
1. Extrae los requisitos del mensaje
2. Usa el template en references/prompts.md
3. Ejecuta scripts/generate.py con los parámetros
4. Devuelve la ruta de la imagenEso es todo. Un archivo markdown con metadata en YAML y instrucciones claras de qué hacer.
Cómo Funciona (Tres Niveles de Progressive Disclosure)
Aquí está la magia: carga progresiva en tres niveles.
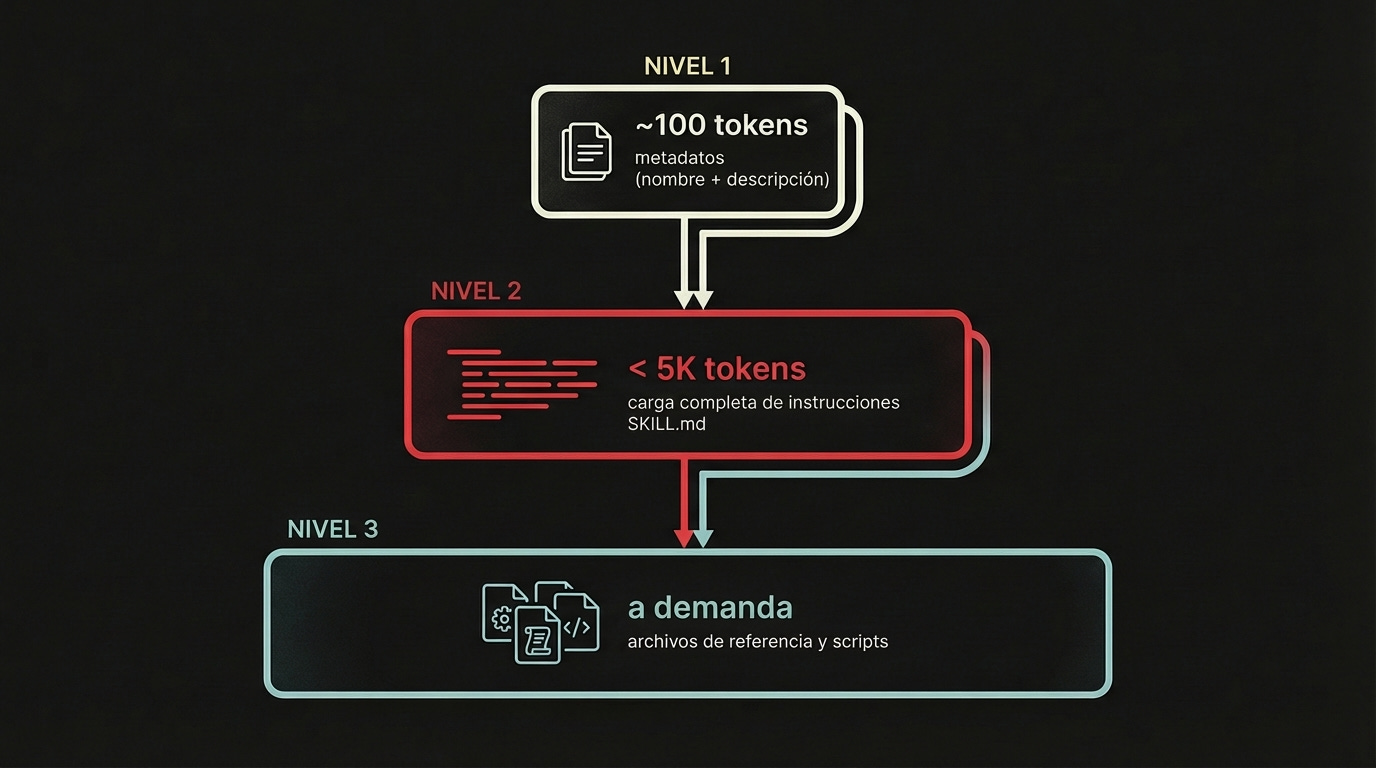
Nivel 1: Metadata (siempre cargado al inicio)
Al inicio, el agente lee solo el
nameydescriptionde la metadata YAML de todos los skillsCosto: ~100 tokens por skill (según especificación oficial)
Ejemplo: “image-generation: Usa este skill para crear ilustraciones o contenido visual con Gemini API”
Nivel 2: Instrucciones completas (cargado cuando es relevante)
Usuario dice: “Necesito una imagen de un taco volador”
Agente evalúa el contexto: “Esto requiere image-generation”
Lee el
SKILL.mdcompleto vía filesystemCosto: menos de 5k tokens (recomendación oficial: mantener SKILL.md bajo 500 líneas)
Nivel 3: Referencias y scripts (cargado según se necesite)
Las instrucciones dicen: “usa el template en references/prompts.md”
Agente lee solo ese archivo
Las instrucciones dicen: “ejecuta scripts/generate.py”
Agente ejecuta el script, solo el output entra al context window (no el código)
Por qué esto es diferente
Antes: “Tengo 10 habilidades. Aquí están todas las instrucciones. Improvisa cuando el usuario pida algo.”
Ahora: “Tengo 10 habilidades (metadata: 1k tokens). Ah, ¿necesitas imágenes? Déjame cargar esas instrucciones específicas. Ah mira ya tengo un script no necesito crearlo. Lo ejecuto y te devuelvo el resultado.”
La diferencia:
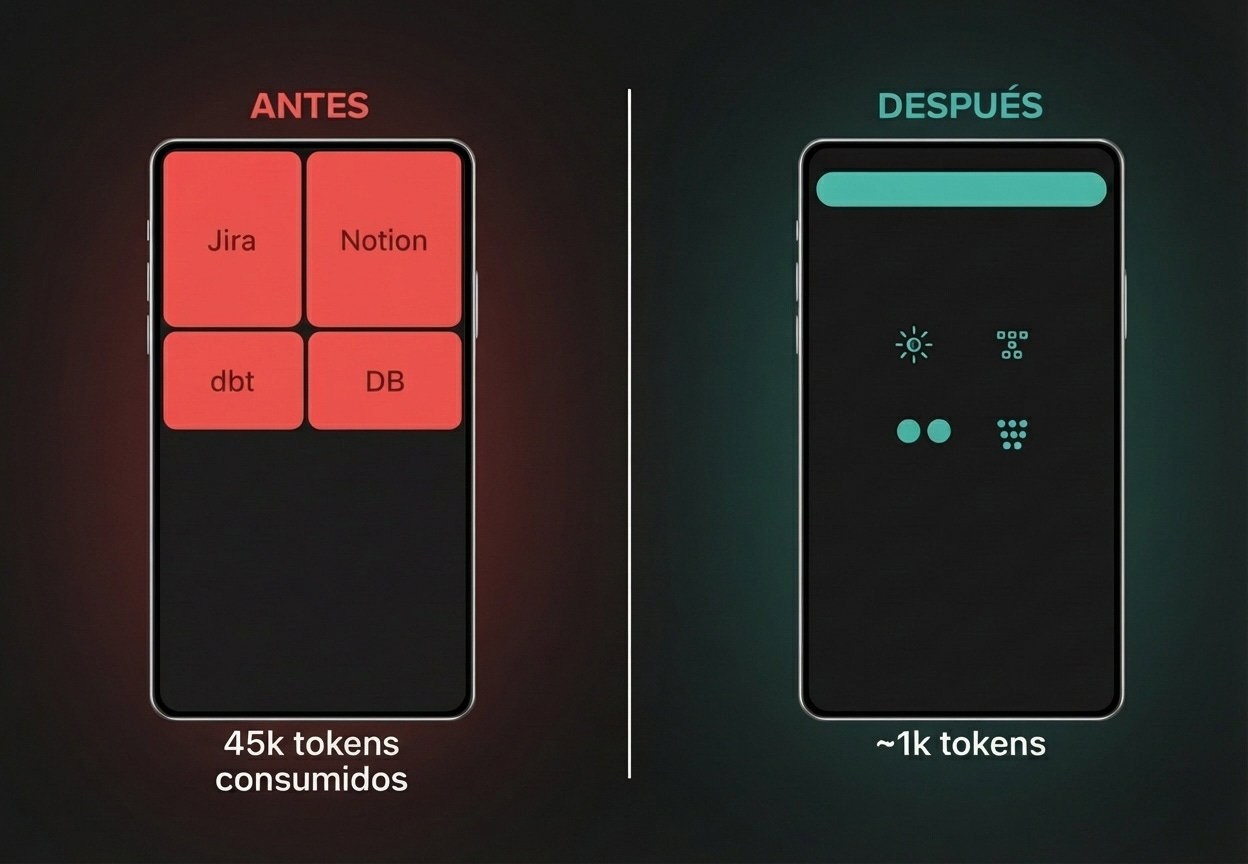
10 habilidades sin Skills: En mi experiencia, 50k+ tokens cargados desde el inicio (varía según tus MCPs)
10 habilidades con Skills: 1k tokens de metadata (antes de cargar instrucciones), cargas solo lo que necesitas cuando lo necesitas
Pero más importante que el ahorro de tokens: consistencia.
Mi Chief of Design combina lo mejor de ambos mundos: el LLM interpreta lo que necesito y genera el prompt dinámicamente, pero la ejecución pasa por un script probado. Inteligencia flexible arriba, confiabilidad abajo.
Volviendo al problema de los MCPs
Skills no reemplazan todos los MCPs. Pero me hicieron replantear cuáles realmente necesito.
Lo que hice:
Desactivé Atlassian y Notion. Los activo solo cuando los necesito
Eliminé el MCP de dbt completamente. En su lugar, documenté en mi CLAUDE.md cómo uso dbt
Yo tengo un alias uvr para uv run, entonces para correr un modelo escribo uvr dbt run -s <modelo>. Esa es mi convención. El agente no necesita un MCP para eso. Necesita saber cómo yo trabajo.
Entre mi CLAUDE.md y un skill que creé para dbt, el agente sabe:
Usar
uvren lugar deuv runLos diferentes targets que usamos en el trabajo (dev, staging, prod)
Usar
snow(el CLI de Snowflake) para queries SQL en lugar del MCP de dbtOtras preferencias personales y de equipo
Skills y CLAUDE.md trabajan juntos para estandarizar tu workflow personal. En lugar de que el agente improvise cómo usar dbt, le digo exactamente cómo lo uso yo.
El resultado: de 95k tokens al inicio, bajé a menos de 1k.
La lección: No todo necesita un MCP. A veces, instrucciones claras en un skill o en tu CLAUDE.md son suficientes. Y mucho más ligeras.
MCP sigue siendo útil cuando necesitas acceso autenticado y bidireccional a servicios externos. Atlassian para crear issues en Jira y buscar en Confluence. Notion para consultar documentación del equipo. Esas son cosas que un comando CLI no puede hacer.
Pero para herramientas que tienen buen CLI (como dbt o gh para GitHub), un skill con los comandos correctos es todo lo que necesitas.
El momento de la estandarización (por qué importa ahora)
Anthropic inventó Agent Skills y lo liberó como estándar abierto el 18 de diciembre de 2025. La especificación vive en agentskills.io.
Anthropic también donó MCP a la Agentic AI Foundation bajo la Linux Foundation, junto con OpenAI y Block. El ecosistema de estándares abiertos para agentes está creciendo.
Quién ya lo soporta
Claude (Claude.ai, Claude Code)
OpenAI Codex (CLI y extensión para IDEs)
Por qué estandarización importa
Escribe un skill una vez. Úsalo en cualquiera de estas herramientas.
No estás apostando a un vendor. Estás invirtiendo en un formato portátil.
Compara con el caos anterior: cada herramienta tenía su propia forma de extender agentes. Prompts personalizados aquí, plugins allá, configuraciones distintas por todos lados. Skills unifican eso.
