
Datos abiertos de México: de cero a dashboard con Claude Code y Opus 4.6
De datos.gob.mx a visualización en vivo, actualizándose sola cada hora

Este jueves hice un livestream analizando datos abiertos del gobierno mexicano con agentes de inteligencia artificial. Dos horas y media, desde cero, y terminamos con un dashboard de calidad del aire que se actualiza solo cada hora.
Es la tercera parte de la serie. En la primera parte] creamos un dashboard brutalista con mis datos de Spotify. En la segunda lo llevamos a tres páginas interactivas con network graphs y galerías de álbumes. Ahora: datos públicos de México que cualquiera puede usar.
Lo que importa ya no es saber exactamente cómo codear algo. Es tu creatividad y tu criterio. Las habilidades técnicas se delegan. El criterio, no.
Lo que construimos
Un dashboard de calidad del aire usando datos de SINAICA (Sistema Nacional de Información de la Calidad del Aire):
20 estaciones de monitoreo en México
PM2.5, O3, CO con umbrales de la norma oficial mexicana
Mapa interactivo de estaciones
Indicadores de frescura: fresco (< 6h), tibio (6-24h), stale (> 24h)
Actualización automática cada hora via GitHub Actions
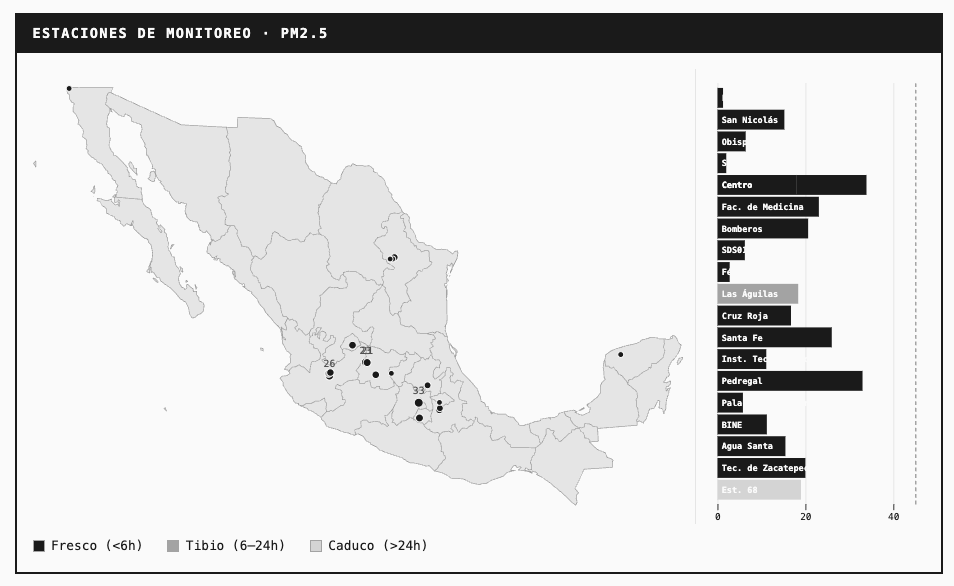
→ Dashboard: chekos.github.io/datos-gob-en-vivo-2026
Además, creamos perfiles técnicos de 10 datasets de datos.gob.mx listos para que alguien más los visualice.
Herramientas
Claude Code: Agente de IA en la terminal
UV: Gestor de paquetes Python
Monologue: Speech-to-text para dictar instrucciones
Observable Plot: Visualizaciones en JavaScript
GitHub Pages: Hosting gratuito
GitHub Actions: Automatización
El workflow
Empezar con agentes en paralelo
Le dije a Claude: “Quiero organizar este repositorio como un proyecto de datos. El producto final va a ser una página de GitHub Pages con Observable Plot para las visualizaciones. Y en lo que estás creando eso, me gustaría que crearas un agente en el background en paralelo que vaya y explore la página de datos.gob.mx y me dé algunas ideas de datasets interesantes.”
Mientras yo veía el portal, los sub-agentes lo navegaban en paralelo. Volvieron con 10 datasets de más de 1,000 disponibles:
Esperanza de vida (CONAPO) — 120 años de datos demográficos
Inversión extranjera directa — flujos por país, sector, estado
Calidad del aire SINAICA — API en tiempo real
Ocupación hotelera, tarifas de electricidad, incidencia delictiva...
Para cada uno creamos un “data profile”: estructura técnica, cobertura temporal/geográfica, recomendaciones de visualización.
Aterrizar en uno
De los 10, aterrizamos en SINAICA. Tenía API funcional, datos en tiempo real, y potencial para algo que viviera solo.
Nota para quienes trabajan en gobierno: datos.gob.mx tiene dos plataformas corriendo en paralelo — Sistema Ajolote (la nueva) y CKAN (la anterior). Nuestros agentes encontraron ambas. Uno usó la API de CKAN, el otro la interfaz nueva. Después, el equipo del portal nos contactó porque algunos datasets no aparecían en la interfaz actual. Documentamos qué pasó.
Dónde entra el criterio
“No necesitas cloud storage”
Alguien en el chat preguntó cómo íbamos a guardar tantos datos. Mi respuesta: no ocupamos. Es un JSON pequeño que reescribimos cada hora en el repositorio de GitHub. Sin base de datos, sin cloud storage.
Eso viene de saber cómo funcionan estos sistemas. Llevo 5 años utilizando github actions y github repos para proyectos así. Sin cloud storage ni database.
“Podríamos hacer un mapa”
El primer draft tenía puras barras. Pero los datos incluyen latitud y longitud.
Le dije a Claude: “Como tienes longitud y latitud, podríamos hacer un mapa muy interesante que serviría como una buena ancla visual en nuestra dashboard. Quizás pudiéramos hacer eso, el primer gráfico presente para llamar la atención. Dame mínimo tres opciones.”
Se me ocurrió después de ver la primera versión — porque he trabajado en visualización y sé qué funciona.
“¿Me puedes explicar por qué solo hay ocho estaciones?”
Pedí 20 estaciones, solo 8 respondieron. En lugar de decir “arréglalo”, pregunté: “¿Me puedes explicar por qué solo hay ocho estaciones ahorita? Creí que teníamos como 20.”
Claude pensó el problema en voz alta: probablemente IDs incorrectas o estaciones fuera de línea. Fue, verificó cuáles estaban activas, y ajustó.
Es más importante tener las preguntas correctas que las respuestas. Cuando le dices “explícame por qué”, el modelo se auto-corrige mejor.
Tips del live
Plan Mode. Dile a Claude que entre en plan mode antes de ejecutar. Te muestra lo que va a hacer y te pide aprobación. Evitas sorpresas. By the way: cuando apruebas el plan, puedes usar “yes + clear context” — los tokens que gastaste pensando se borran y empiezas la ejecución con contexto limpio.
Pide 3 opciones. En lugar de pensar tú la solución, di “dame tres propuestas”. Claude te presenta opciones, tú escoges. Te desbloqueas más rápido y a veces encuentra soluciones que no se te habrían ocurrido.
Screenshots para debugging. Cuando algo visual no se ve bien, toma captura y pásasela a Claude. Entiende imágenes y puede diagnosticar problemas que serían difíciles de describir con texto.
Pregunta “¿por qué?” en lugar de “arréglalo”. Si algo falla, no pidas que lo arregle. Pregunta por qué falló. Tú aprendes, y Claude piensa el problema en voz alta — se auto-corrige mejor cuando entiende el contexto.
El repo
→ Código: github.com/chekos/datos-gob-en-vivo-2026
Incluye:
Dashboard funcional de calidad del aire
10 data profiles de datasets mexicanos
GitHub Action para actualización automática
Todo el código que Claude escribió
Clónalo, explóralo, adáptalo. O dile a tu Claude Code que lea los profiles y construya algo con otro dataset.
La inteligencia artificial no reemplaza saber analizar datos. Lo multiplica.
Si no sabes qué preguntas hacer, Claude no te va a salvar. Pero si ya tienes la intuición, si ya sabes qué buscar, Claude te deja llegar ahí en una fracción del tiempo.
¿Te sirvió esto? Suscríbete a tacosdedatos.com para más sobre IA + datos.