
Datos abiertos de México parte 2: Inversión extranjera, Sankey y mapas interactivos
De API gubernamental a dashboard con filtros dinámicos en 2 horas

🌮 Los workflows de esta serie ahora están en un solo lugar → guias.tacosdedatos.com
Los suscriptores premium tendrán acceso gratuito a esta guía (y futuras guías) como parte de su suscripción.

¿De dónde viene el dinero extranjero que entra a México? ¿Qué estados ganan? ¿Qué industrias atraen más inversión?
Esas preguntas se pueden responder con datos abiertos del gobierno. Y con Claude Code, puedes tener las respuestas visualizadas en dos horas.
Las habilidades técnicas se delegan. El criterio, no.
Este es el cuarto live de la serie. En la primera partecreamos un dashboard brutalista con mis datos de Spotify. En la segunda lo llevamos a tres páginas interactivas. En la tercera construimos un dashboard de calidad del aire que se actualiza solo.
Ahora: inversión extranjera directa. Mapas, Sankey, filtros interactivos.
Por qué este dataset
De los 11 perfiles que creamos en el live anterior, IED me llamó la atención por tres razones:
Tiene dimensión geográfica. Puedo hacer mapas. Los mapas se ven chidos.
Tiene flujos. País → Estado → Sector. Perfecto para un Sankey.
Es relevante. Con todo el tema del nearshoring, quería ver qué tan real es la inversión que está llegando.
Spoiler: CDMX se lleva casi todo. Pero eso ya lo sospechaba. Lo interesante es ver el cómo.
Lo que construimos
Un dashboard de Inversión Extranjera Directa usando datos de la Secretaría de Economía:
Mapa coroplético de inversión por estado con tratamiento especial para CDMX (el outlier con $14 mil millones)
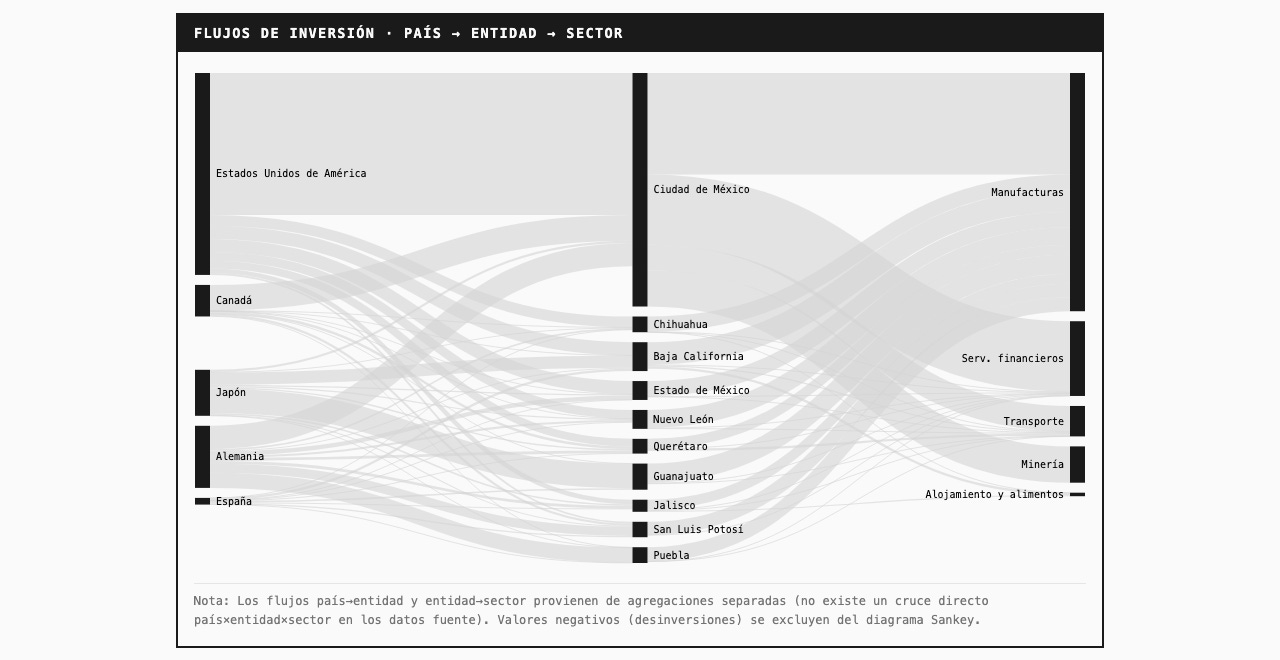
Diagrama Sankey mostrando flujos: país de origen → estado → sector económico
Top industrias por estado con barras horizontales
Filtros interactivos para explorar por país o por sector
→ Dashboard en vivo: chekos.github.io/datos-gob-en-vivo-2026/ied.html
También creamos el perfil técnico de un nuevo dataset: Remesas, inspirado por un análisis de small multiples que vi en tuirer.
Herramientas
Claude Code: Agente de IA en la terminal (Opus 4.6)
UV: Gestor de paquetes Python
Monologue: Speech-to-text para dictar instrucciones
Observable Plot: Visualizaciones declarativas en JavaScript
D3: Para el diagrama Sankey
GitHub Pages: Hosting gratuito
El workflow
Empezar desde el contexto anterior
El repositorio ya existía del live anterior. La dashboard de calidad del aire ya estaba funcionando y actualizándose cada hora.
Le dije a Claude: “Quiero crear una nueva página para otro dataset. Hazme preguntas para definir el proyecto.”
Me hizo cinco preguntas. No le di respuestas perfectas—le dije lo que quería ver, no cómo hacerlo.
Definir la visión, no la implementación
“Quiero un mapa coroplético arriba como ancla visual. Debajo, un heatmap interactivo donde pueda filtrar por país de origen o por industria. Y al final, un diagrama Sankey que muestre los flujos de país hacia estado hacia sector.”
Eso fue todo. No mencioné qué biblioteca usar, ni cómo estructurar los datos, ni el CSS. Solo la visión.
Tip: Los mapas son buenas anclas visuales. Llaman la atención y dan contexto geográfico inmediato.
El problema de CDMX (y cómo lo resolvimos)
Aquí es donde se puso interesante.
CDMX tenía $14 mil millones en inversión. El siguiente estado tenía una fracción de eso. En el primer mapa, CDMX era el único estado oscuro. Todo lo demás era casi blanco. No servía para nada.
Claude propuso usar quantiles: dividir los 32 estados en 5 grupos iguales. Pero eso escondía la magnitud real. Si divides en grupos iguales, pierdes la historia de que CDMX es un monstruo comparado con el resto.
Le dije: “No me convence. ¿Qué otras opciones hay?”
La solución que encontramos: hatching. Pintar CDMX con un patrón rayado diferente y agregar una anotación con el valor exacto. Así se ve que es un caso especial sin distorsionar la escala del resto.
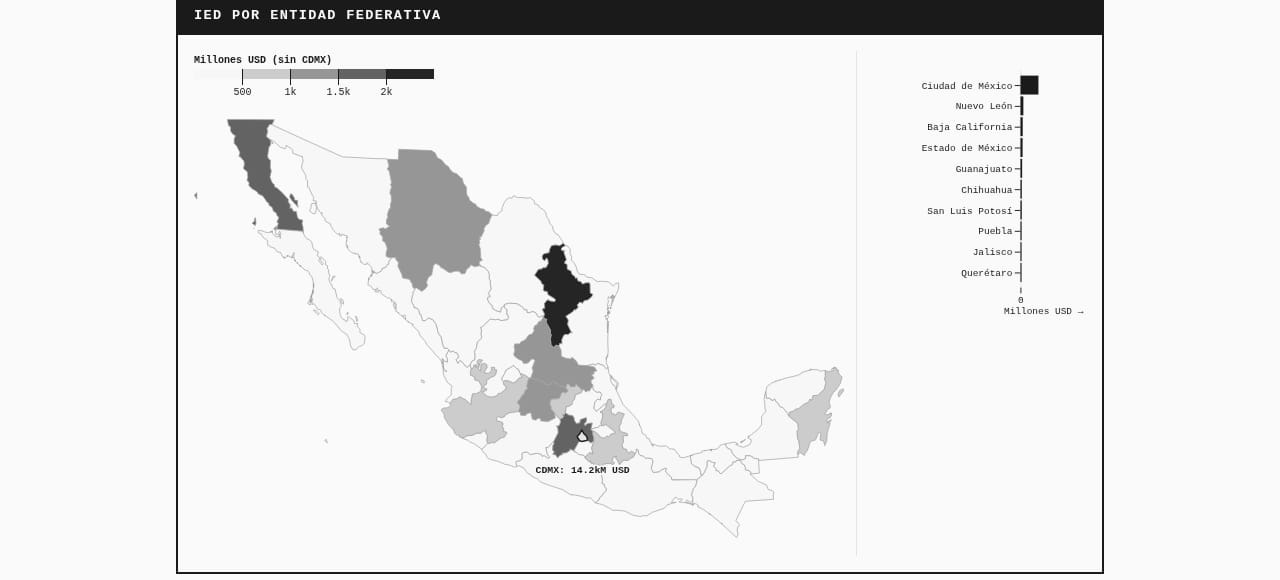
El hatching viene de la visualización de datos de hace décadas, cuando solo tenías blanco y negro para publicar. Diferentes patrones para diferentes categorías. Me gustó que Claude lo sugiriera—no era la solución obvia.
Sankey para mostrar los flujos
El diagrama Sankey muestra de dónde viene el dinero y hacia dónde va:
Izquierda: País de origen (USA, España, Japón, Alemania...)
Centro: Estado receptor (CDMX, Nuevo León, Jalisco...)
Derecha: Sector económico (Manufactura, Servicios financieros...)
El primer intento funcionaba pero era estático. Le pedí que cuando hiciera hover en una sección, se resaltaran todos los flujos conectados.
Pequeño detalle que hizo la diferencia: los tooltips de CDMX tapaban otros estados cuando hacías hover. La solución fue obvia una vez que la vimos—si ya tienes anotación con el valor, no necesitas tooltip. Pero me tomó verlo en vivo para darme cuenta.
Agentes en paralelo
Mientras trabajábamos en el dashboard principal, lancé otro agente en una terminal separada para crear el perfil técnico de Remesas.
Cada agente tiene su propia ventana de contexto. Puedo tener uno construyendo y otro investigando sin que se estorben. Dos terminales, dos conversaciones, cero interferencia.
Tips del live
Plan Mode antes de ejecutar. Cuando el plan es complejo, dile a Claude que entre en plan mode. Te muestra los pasos antes de hacer cambios. Evitas sorpresas.
“Yes + clear context”. Después de que Claude te muestra un plan largo, puedes aprobarlo Y limpiar el contexto. Los tokens que gastó pensando se borran. Más espacio para iterar.
Commits automáticos. Dile a Claude que haga los commits. Los mensajes quedan detallados y atómicos. Cuando vuelvas al proyecto después, puedes preguntarle “¿cómo resolvimos esto?” y tiene el historial de git para responder. Tu yo del futuro te lo agradece.
Dicta, no escribas. Con speech-to-text le das mucho más contexto. Explicas el por qué, no solo el qué. Mejores instrucciones = mejores resultados.
El repositorio
→ Código: github.com/chekos/datos-gob-en-vivo-2026
Ahora incluye:
Dashboard de calidad del aire (actualización automática cada hora)
Dashboard de inversión extranjera directa
11 perfiles técnicos de datasets de datos.gob.mx
GitHub Action para actualización automática
Clónalo, explóralo, o dile a tu Claude Code que lea los perfiles y construya algo con otro dataset.