Ayer visitando el tuiter-espacio me encontré esta queja de python:
 Irving MA@moaimx
Irving MA@moaimx Odio python y su manera de romperse cuando instalas algo que no le gusta... y no, no voy a estar haciendo virtual envs cada que quiero analizar una maldita base de datos. Y ya, ese es todo el tuit03:52 AM - 24 Mar 2022
Odio python y su manera de romperse cuando instalas algo que no le gusta... y no, no voy a estar haciendo virtual envs cada que quiero analizar una maldita base de datos. Y ya, ese es todo el tuit03:52 AM - 24 Mar 2022


Tan común que tiene su propio comic de XKCD
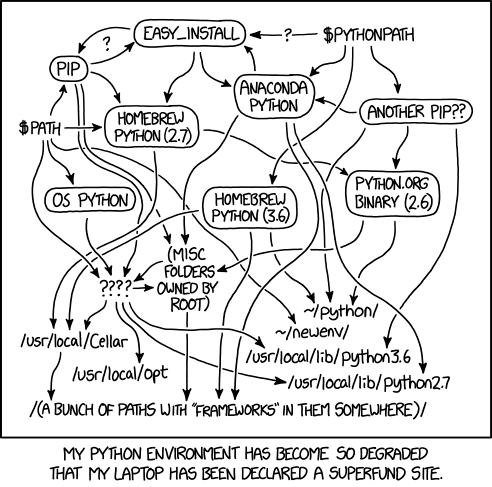
Los entornos virtuales en python es de los conceptos mas difíciles de explicar a principiantes y es algo importantísimo tanto para desarrolladoras de software como quienes trabajamos con datos. No importa cuantos años tengas trabajando con python, siempre vas a tener problemas con tus entornos virtuales.
Cada cierto tiempo aparece una nueva herramienta para manejar entornos virtuales - poetry, virtualenv, conda. Ya parece javascript sacando un nuevo framework cada semana 😛
Python incluye una biblioteca (venv) en su (biblioteca estándar (standard library) para crear entornos virtuales (documentación oficial de python en español).
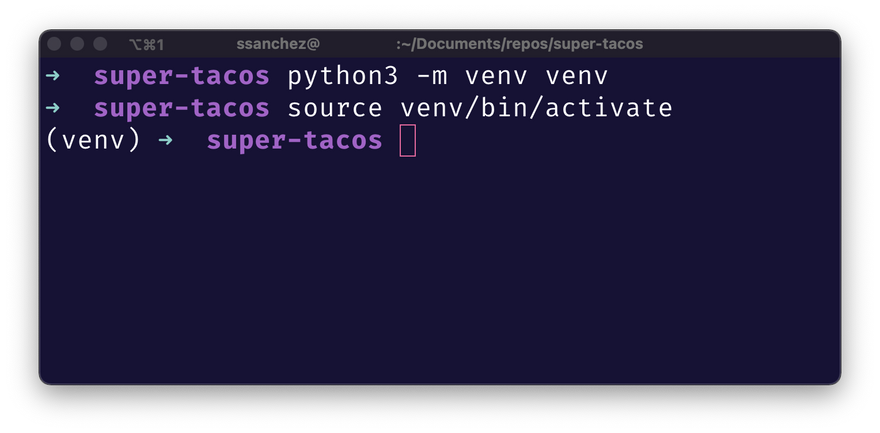
Puedes crear un entorno virtual de la siguiente manera:
python3 -m venv camino/al/directorio/nombre_del_entorno
O sea, si yo estoy en mi terminal y quiero ir a un directorio "repos" en mi directorio "Documents", crear un nuevo directorio donde voy a comenzar un nuevo proyecto llamado "super-tacos", crear un nuevo entorno virtual e instalar pandas, pyjanitor, sidetable, rich, altair, jupyter y pip-chill (como siempre lo hago 😩) - tengo que hacer todo esto en mi terminal:
# me voy a repos
cd Documents/repos
# creo directorio pa'l proyecto
mkdir super-tacos
cd super-tacos
# creo mi entorno e instalo paquetes
python3 -m venv venv
source venv/bin/activate # en MacOS lo activas usando source
python3 -m pip install --upgrade pip
python3 -m pip install pandas pyjanitor sidetable rich altair jupyter pip-chill
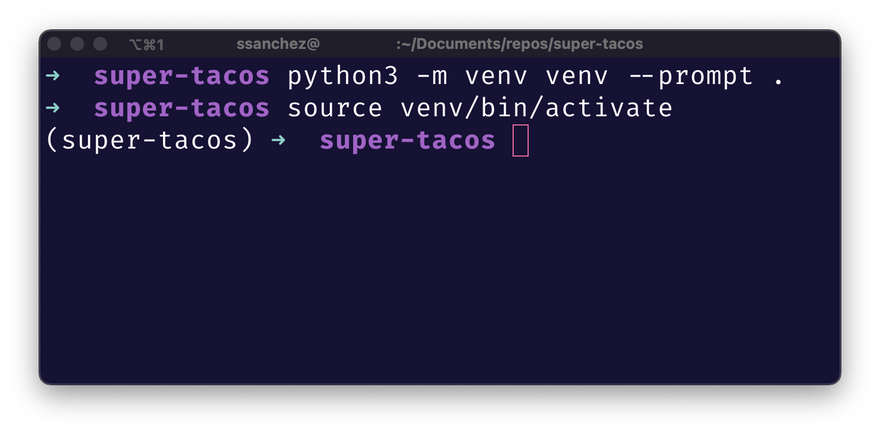
Por defecto, tus nuevos entornos virtuales se llaman Si le pasas el argumento 💡 tip #1
¿Sabías que puedes darle nombre a tu entorno virtual? A partir de python 3.6 puedes pasar el argumento --prompt para pasar una string que aparece en tu terminal cuando esta este entorno activado.
venv:
--prompt . (con el . significando "este directorio en el que nos encontramos") tu nuevo entorno virtual compartirá nombre con el directorio de tu proyecto
DRY - Don't Repeat Yourself
De hecho, yo se que esto de la filosofía DRY es más complejo (creo ?) pero me gustan los acrónimos. El punto es: si estás haciendo algo similar muy seguido, tal vez puedas automatizarlo.
En mi caso, yo creé una función de shell (un script de shell en wikipedia lo llaman "guión de concha" 😂 enlace). Esencialmente, estos comandos en la terminal (cd aquí, mkdir esto, crear el entorno, instalar paquetes) son los mismos con cada proyecto. Lo único que estoy cambiando es el nombre del proyecto.
Oportunidad perfecta para la automatización

⚠️ Yo no soy desarrollador de software y no utilizo shell "profesionalmente". Es decir, yo utilizo scripts de shell/bash para resolver mis problemas. Esto significa que tal vez no sea la manera mas eficiente de resolverlos y si tu sabes de esto me deberías dejar un comentario con tus recomendaciones 👀 plis 🙏
Mi función es la siguiente:
#!/bin/bash
function newrepo()
{
NEW_REPO="$HOME/Documents/repos/$1"
mkdir "$NEW_REPO" || echo "$1 already exists in repos/"
cd "$NEW_REPO" || exit
git init
echo "# $1" > README.md
print ".ipynb_checkpoints/\n__pycache__/\n.venv/\nvenv/\n" > .gitignore
python3 -m venv venv
source venv/bin/activate
python3 -m pip install --upgrade pip
python3 -m pip install pandas pyjanitor sidetable rich altair jupyter pip-chill
pip-chill --no-chill > requirements.txt
}
Vayamos por partes:
NEW_REPO="$HOME/Documents/repos/$1"
mkdir "$NEW_REPO" || echo "$1 already exists in repos/"
cd "$NEW_REPO" || exit
La primera línea esta creando una string insertando dos variables. $HOME el cual es el directorio ~ (el directorio en el que te encuentras por defecto al abrir la terminal). La variable $1 representa el primer valor que le pasas a la función newrepo. Desde mi terminal puedo escribir newrepo super-tacos y ese segundo cachito de texto (el primero después de llamar la función) "super-tacos" es el valor de $1. Si le pasara más argumentos, se guardarían en variables $2, $3 y así sucesivamente.
Mi nueva variable NEW_REPO entonces se vuelve "~/Documents/repos/super-tacos".
La segunda línea tiene el operador || que es equivalente a or o | en otros lenguages. Es decir, "haz esto o, si no puedes, haz esto." Entonces esta segunda línea dice "crea el directorio NEW_REPO o si no se puede, por alguna razón, escribe (echo) 'super-tacos ya existe'" (ya que 'super-tacos' es el valor de la variable $1. Aquí estoy asumiendo que la razón por la que no pudimos crear el directorio es por que ya existía otro con el mismo nombre ahí pero técnicamente existen más razones por las cuales podría recibir un error y no poder crear el directorio ahí (tal vez no tengo permiso, tal vez no es un nombre válido, etc). Pero no estoy creando una biblioteca para publicar y que mucha gente la use - este script y esta lógica funciona lo suficiente para mis necesidades. No te claves en la perfección, plebe.
En la tercera línea intentamos entrar a este nuevo directorio (cd de change directory). Puedes ver el operador || de nuevo. Aquí, si por alguna razón no podemos entrar al nuevo directorio vamos a terminar todo (exit).

git init
echo "# $1" > README.md
print ".ipynb_checkpoints/\n__pycache__/\n.venv/\nvenv/\n" > .gitignore
python3 -m venv venv
Las siguientes 4 líneas hacen lo siguiente:
- Inicializar
gitpara el control de versiones - Crear un archivo README.md con la línea "# super-tacos" (como un título en markdown -
#= "Header 1" =<h1>) - Crear un archivo
.gitignorecon 4 líneas:-
.ipynb_checkpoints/- jupyter produce estos automáticamente -
__pycache__/- python produce estos automáticamente -
.venv/- hay gente que utiliza.venvpara su entorno virtual -
venv/- nosotros utilizamosvenven este script
-
- Creamos el entorno virtual
💡 Usamos print en lugar de echo para crear el .gitignore ya que estamos utilizando el caracter \n que significa "nueva línea" y echo no lo maneja. Pero print y echo hacen esencialmente lo mismo.
Hasta aquí podríamos terminar nuestro script. Ya creamos un nuevo directorio, inicializamos git y creamos nuestro entorno virtual. Si abrimos este directorio en VS Code, VS Code va a encontrar este entorno virtual automáticamente. Aun te va a pedir que confirmes que ese es el entorno virtual que quieres utilizar pero ahora solo estas a un click de comenzar tu análisis de datos.
source venv/bin/activate
python3 -m pip install --upgrade pip
python3 -m pip install pandas pyjanitor sidetable rich altair jupyter pip-chill
pip-chill --no-chill > requirements.txt
Las siguientes 4 líneas toman más tiempo en ejecutarse y si no fuera porque en serio uso python y estos paquetes para la gran mayoría de mis proyectos no las incluiría.
- Activamos nuestro entorno virtual.
- Actualizamos
pip. - Instalamos bibliotecas que casi siempre uso.
- Utilizamos la biblioteca
pip-chillpara crear unrequirements.txtmás sencillo que el comúnpip freeze
No incluye ¿qué es pip-chill?
pip-chill es como pip freeze pero muestra solo los paquetes que no son dependencias de otros paquetes. Por ejemplo, pyjanitor y sidetable son librerías que extienden la funcionalidad de pandas y cuando las instalas también instalas pandas (si no lo tienes instalado). Esto significa que tu requirements.txt no necesita incluir pandas. Mi requirements.txt normalmente se ve así:
altair==4.2.0
jupyter==1.0.0
pyjanitor==0.22.0
rich==12.0.1
sidetable==0.9.0
pandas porque al instalar estas bibliotecas también vas a instalar pandas.
Como usar newrepo desde la terminal
Yo utilizo Oh My Zsh
Zsh es un shell, como bash o fish, que interpreta comandos y los ejecuta. Oh My Zsh es un framework construido sobre zsh que está estructurado para permitirle tener plugins y temas, así como proporcionar lo que creemos que son las mejores configuraciones desde el principio. Puedes usar zsh sin Oh My Zsh, pero no puedes usar Oh My Zsh si no tienes zsh.
Y cada que abro mi terminal se ejecuta el archivo ~/.zshrc (así es como tengo las funcionalidades de zsh cada que "inicio una sesión" en mi terminal.)
Ahora puedo guardar mi función newrepo en un archivo .my_aliases (o como quiera llamarle) y en ~/.zshrc agrego la línea
source ~/.my_aliases
Ya que guardé mi archivo .my_aliases en el mismo directorio que .zshrc (o sea, ~ o $HOME).
Ahora, cada que abra una terminal zsh va a también ejecutar el código de .my_aliases y definir la función newrepo.
Ahora, simplemente utilizo newrepo <NOMBRE_DE_MI_PROYECTO> desde la terminal y tengo un nuevo directorio con un entorno virtual de python listo para explorar datos. Todo con un solo comando.
Siguientes pasos
Esto funciona para mi por que:
- Todos mis proyectos los creo en el directorio
Documents/repos/ - Casi siempre voy a utilizar python y estos paquetes
Lo importante aquí es que podemos automatizar procesos repetitivos. Yo estoy utizando venv de python pero igual pudieramos automatizar la creación de un entorno conda o un proyecto con poetry.
shell no es un lenguaje que practico mucho y no es tan común en el mundo de los datos (es mas común de lo que creemos pero nadie tuitea como 'mira mi nuevo script de shell para rascar datos de esta página y analizarlos automáticamente' como lo hace la gente de python o R.)
Te dejo unas herramientas que he utilizado para trabajar con datos desde la línea de comandos con shell:
-
jq- trabajar con JSON https://stedolan.github.io/jq/ -
visidata- trabaja con datos tabulares https://www.visidata.org/ -
mapshaper- transforma archivos cartográficos https://github.com/mbloch/mapshaper -
csvs-to-sqlite- transforma CSVs en bases de datos SQLite https://github.com/simonw/csvs-to-sqlite -
ffmpeg- manipula video y audio https://ffmpeg.org/ (este esta chido conyoutube-dlhttp://ytdl-org.github.io/youtube-dl/)

Discussion (0)