
Así es, el mundo necesita otro tutorial de cómo hacer una nube de palabras...
Para la suerte del mundo, existe un paquete llamado wordcloud que hace todo el trabajo por nosotros. Lo interesante que haré en este post es enseñarte cómo hacer esa nube un poco más interesante y atractiva, algo que debes seriamente considerar si quieres llamar la atención de la gente.
En este caso, trataré de hacer una nube de palabras que luzca como el emoji de la banderita roja 🚩.
Para comenzar, usaré paquetes conocidos en la ciencia de datos: nltk, pandas, pillow, matplotlib, pero además hay instalar wordcloud y unidecode:
pip install -q wordcloud
pip install -q unidecode
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import nltk
import string
import unidecode
import wordcloud
import PIL
import collections
import random
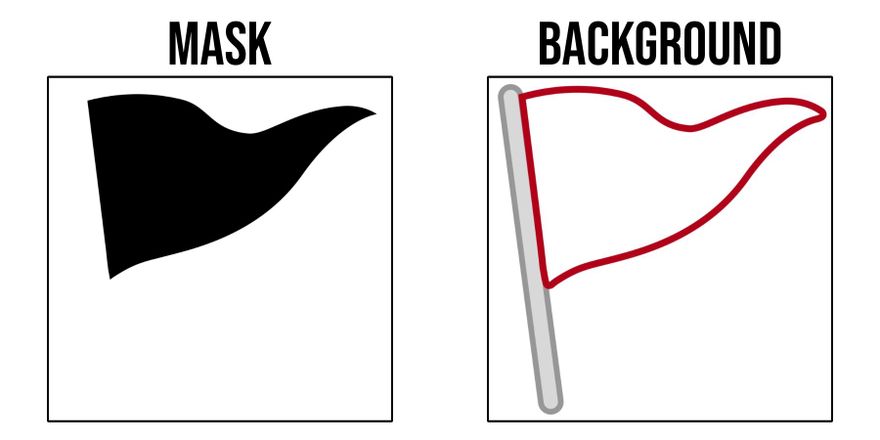
Antes de continuar, hay que descargar un par de imagenes auxiliares para crear la nube:
- Una máscara, que debe ser una imagen blanco y negro en donde la porcion obscura de la imagen es el espacio que usará la nube de palabras, mientras que la porcion blanca será el fondo.
- Un fondo, que usaré como fondo de la imagen final, en este caso es el contorno del emoji de la bandera roja.
Aquí es en donde tu implementación podría variar de la mía, podrías tu usar otras imagenes.
Las mías las descargo de internet usando wget:
wget -O flag.jpg -q https://ik.imagekit.io/thatcsharpguy/other_sites/kaggle/flag.jpg?updatedAt=1647703191239
wget -O flag-definitive.jpg -q https://ik.imagekit.io/thatcsharpguy/other_sites/kaggle/flag-definitive.jpg?updatedAt=1647703191398
wordcloud es tan flexible que permite trabajar directamente con texto directamente, sin embargo, los tweets no son cualquier tipo de texto, y es por eso que hay que preprocesarlo de forma especial. Voy a crear una función llamada tokenise que tome una cadena de texto y regresae una lista de tokens.
spanish_stopwords = nltk.corpus.stopwords.words('spanish')
punctuation = string.punctuation + "¿¡"
stopwords = set(spanish_stopwords + [c for c in punctuation] + ["mas", "si", "aqui", "ser", "...", "asi"])
tokeniser = nltk.tokenize.TweetTokenizer()
starts_with = set(["https://", "#", "@"])
def tokenise(text):
tokens = []
for token in tokeniser.tokenize(text):
_token = unidecode.unidecode(token.lower())
if (
len(_token) > 1 and
(not _token.isnumeric()) and
(not any([ _token.startswith(start) for start in starts_with ])) and
(_token not in stopwords)
):
tokens.append(_token)
return tokens
tokenise("""¡PREPAREN LA BOTANA! 🤩
- Chucky y el Napoli en la Serie A.
- F.A. Cup.
- Bundesliga
- Héctor Herrera y el Atlético.
- Clásico Regio.
#BitácoraRÉCORD 📆
Descarga RÉCORD Plus y obtén la mejor información en todo momento ▶️ https://bit.ly/3oA6dpi""")
Y el resultado es:
['preparen',
'botana',
'chucky',
# ...
'mejor',
'informacion',
'momento']
Con la función tokenizadora lista, podemos cargar los tweets, convertirlos a tokens y llevar la cuenta usando Counter:
twitter = pd.read_csv("/kaggle/input/techtuiter/tech-twitter.csv")
word_count = collections.Counter()
for text in twitter["text"]:
word_count.update(tokenise(text))
Para ver cuáles son los tokens más comunes podemos usar most_common:
word_count.most_common(10)
[('video', 1397),
('hoy', 1387),
('nuevo', 1234),
('hacer', 1087),
('dia', 1062),
('solo', 999),
('bien', 939),
('trabajo', 911),
('mejor', 910),
('curso', 909)]
Ya con la cuenta de tokens, podemos crear nuestra nube usando WordCloud. Los argumentos que hay que pasarle al constructor son:
-
background_color=rgba(255, 255, 255, 0), es decir, transparente. -
mode="RGBA", indica que queremos una imagen con transparencia. -
max_words=2500, quiero que la nube use las 2500 palabras más frecuentes. -
mask=flag_mask, este es tal vez el argumento más importante, y es que esta es la máscara que quiero aplicar
Para terminar, hay que llamar al método generate_from_frequencies pasando el Counter que creamos más arriba.
flag_mask = np.array(PIL.Image.open("flag.jpg"))
wc = wordcloud.WordCloud(
background_color="rgba(255, 255, 255, 0)", mode="RGBA",
max_words=2500, mask=flag_mask).generate_from_frequencies(word_count)
Para mostrar la imagen podemos usar matplotlib.
plt.figure(figsize=(10,10))
plt.imshow(wc)

Hasta ahora todo bien, pero los colores no combinan con la 🚩 que quiero representar. Para nuestra suerte, wordcloud también incluye un método para recolorear la nube de palabras recolor, este método recibe una función que retorne el color de la palabra. Como quiero distintos tonos de rojo, haré que mi función regrese un color en la representación HSL, con variaciones entre 20% y 60%.
def red_colors(word, font_size, position, orientation, random_state=None, **kwargs):
return f"hsl(0, 100%, {random.randint(20,60)}%)"
plt.figure(figsize=(10,10))
plt.imshow(wc.recolor(color_func=red_colors), interpolation='bilinear')

Ya se ve más como una bandera, pero le falta el pequeño palito para ondearla. Así que hay que agregárselo con pillow.
Lo primero es que hay que recuperar las imagenes necesarias. Primero nuestra cloud usando el método to_image y leemos la otra imagen del disco con PIL.Image.open:
cloud = wc.to_image()
staff = PIL.Image.open("flag-definitive.jpg")
Después usamos paste para "pegar" nuestra nube sobre la imagen con el contorno de la bandera:
staff.paste(cloud, (0, 0), cloud)
plt.figure(figsize=(10,10))
plt.imshow(staff, interpolation='bilinear')

Por último guardamos la imagen con save y listo.
staff.save(f"red-flag.jpg", format='JPEG', quality='maximum')
Como siempre, me encuentran en @feregri_no en Twitter por si tienen alguna duda. El código para reproducir el ejemplo está en Kaggle junto con el dataset.




Discussion (1)
No lo sabía!!!, Es demasiado fácil de hacerlo!, Gracias por el post, es hora de intentarlo por mi cuenta.